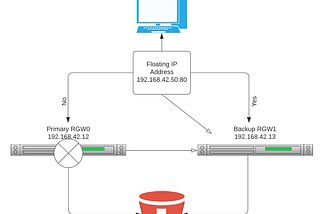
PinnedRaz maabariinNerd For TechCeph-Ansible Deployment & Testing Using Vagrant (Part 2)Following my first part of this medium procedure which mainly focused on the deployment side, today will get more into detail on the…7 min read·Mar 14, 2021----
PinnedRaz maabariinNerd For TechCeph-Ansible Deployment & Testing Using VagrantWhat is and why Ceph?7 min read·Mar 7, 2021----
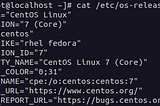
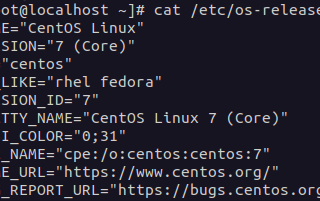
PinnedRaz maabariCentOS to RHEL MigrationNowadays when Red Hat declared stopping their support for the Community enterprise operating system (CentOS), users and enterprises are…3 min read·Feb 8, 2021----
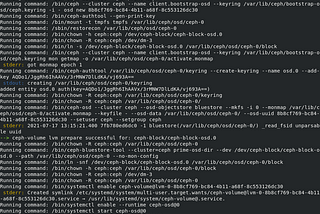
Raz maabariinNerd For TechContainerized Ceph OSD ReplacementNowadays, with every service migrating into microservices, we figured it's time to do so as well on our Ceph cluster as an SDS. While…5 min read·Jul 17, 2021----